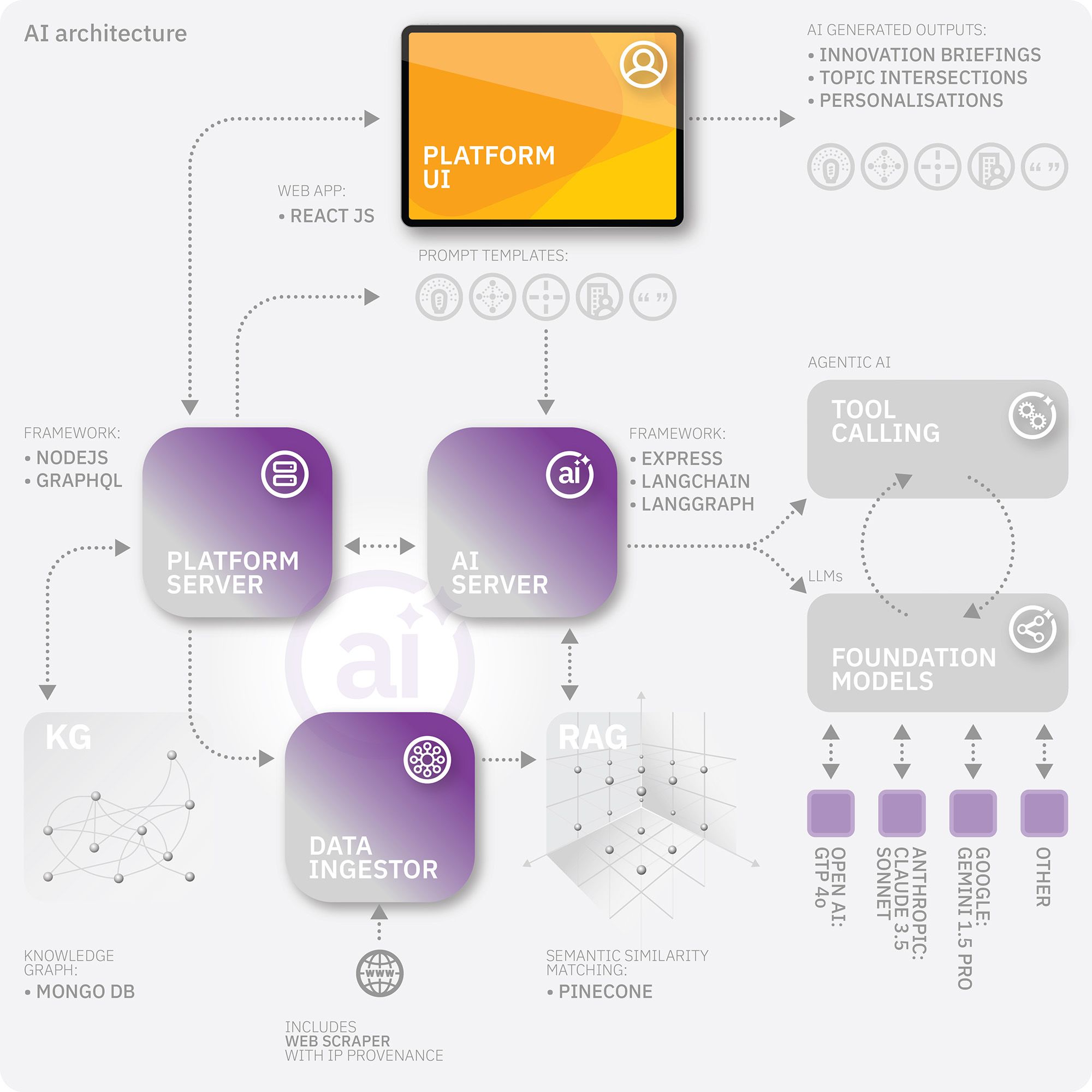
Custom AI Architecture
It already seems a long time since OpenAI released ChatGPT and invoked the promises of productivity through Large Language Models (LLMs). At the time of the OpenAI release, Shapeable was already on the way to becoming an AI-focussed company. We opted to create our own custom AI architecture early on in our LLM R&D phase. This was due to overlapping requirements such as - business cases, international compliance, multi-language, content confidentiality and avoiding roadblocks on technical feature development.
- Our AI technology stack now includes:
- AI Server (written in Express)
- Vector database (Pinecone)
- Knowledge Graph (MongoDB)
- LangChain with LangGraph
- Data Ingestor with Web Scraper (with IP provenance)
- Terraform and Docker, for geo-located instance creation
- Foundation model routing
- AgenticAI tool calling
Our earliest R&D experiments used a third-party Retrieval Augmented Generation (RAG) SaaS solution, with its own vector database. We tested how users could explore large arrays of information and augment the responses using the customers’ proprietary data. Whilst we could generate more nuanced responses than via ChatGPT alone, we also realised this wasn’t capable of deep integration into our platform. We needed to take more control over information retrieval, access permissions, fallback models, and knowledge graph entities.
Also in the R&D stages of our AI development we tested most of the functionality using NodeJS scripts. From the very beginning we knew we wanted to support any LLM model by any provider, so we started building our prototypes using Langchain. This meant we could leverage the abstractions that the framework offered for the entire lifecycle of vendor-agnostic development. To keep the stack consistent, we chose JavaScript as the language. When our initial tests surfaced successful results, we started building the functionality into a NodeJS GraphQL server using TypeScript, to match our platform server.
The GraphQL server worked well in our initial tests, but it was complicated to stream the response text, and it took too long to generate the entire response before sending it back to the user interface. So, we decided to change the server into an Express App and leveraged http server-sent events to stream the text directly from the LLM provider, via the AI server. This helped us stream the responses to an HTTP POST request without complicating things by using web sockets with GraphQL.
We also wanted to ensure that other platform server-related updates wouldn’t hinder the AI’s development, so we built the AI server as a micro-service. This has allowed us to keep our customer’s AI servers up to date with the latest AI advancements while having minimum overheads with other services.
Prompt Templates & Control Flow
Prompt templates for LLMs are not a concept that we invented, but they strongly fit our users’ needs. Instead of staring at an empty question box, wondering what to ask, we also offer a choice of selections which generate specifically formatted outputs, along with citations, based on standardised use cases.
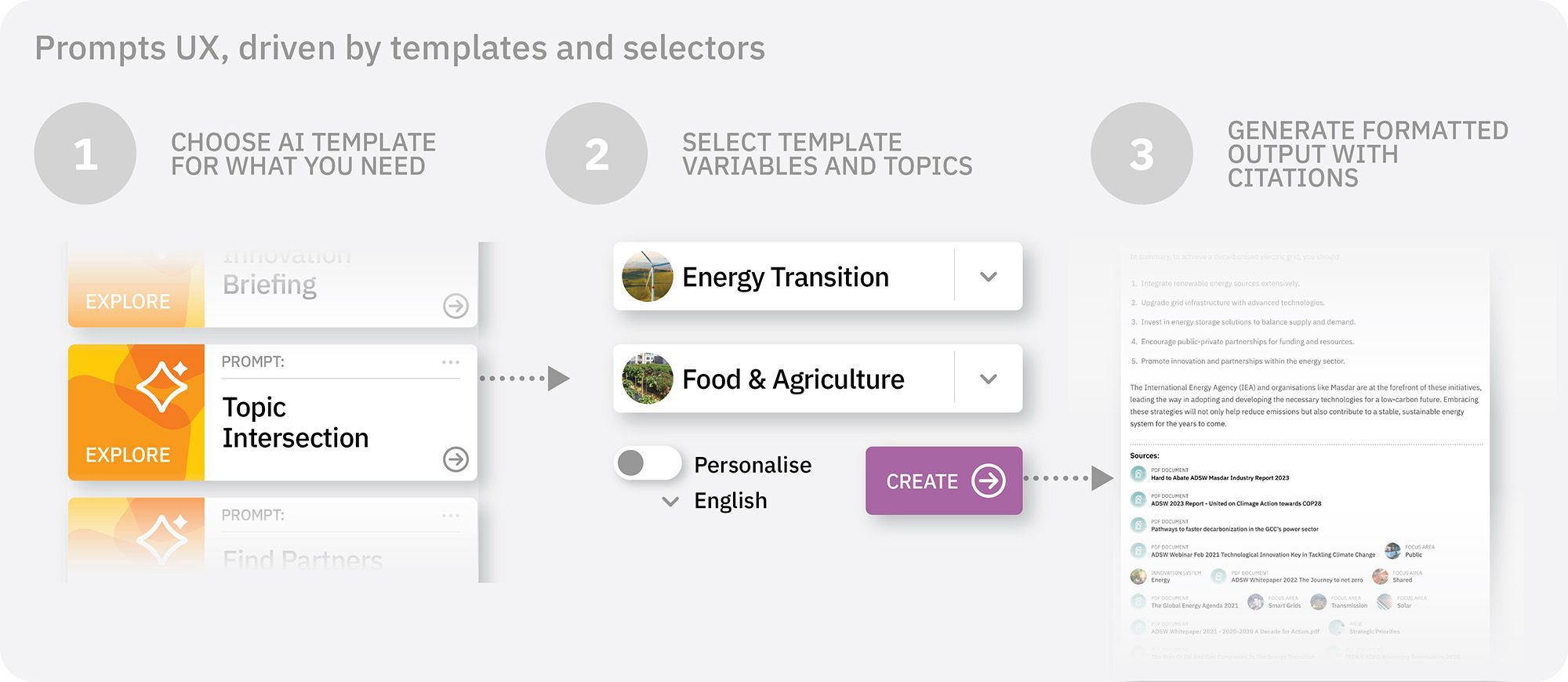
The simple front end interface never shows the detailed instructions and system prompt running in the background. Users can intersect Topics, generate Industry Briefings, get listings of innovative organisations for potential partnerships, output results in multiple languages, and with personalisation based on their user profile.
The architecture of our system ensures our customised AIs are friendly to newcomers and flexible to diverse customer requirements.
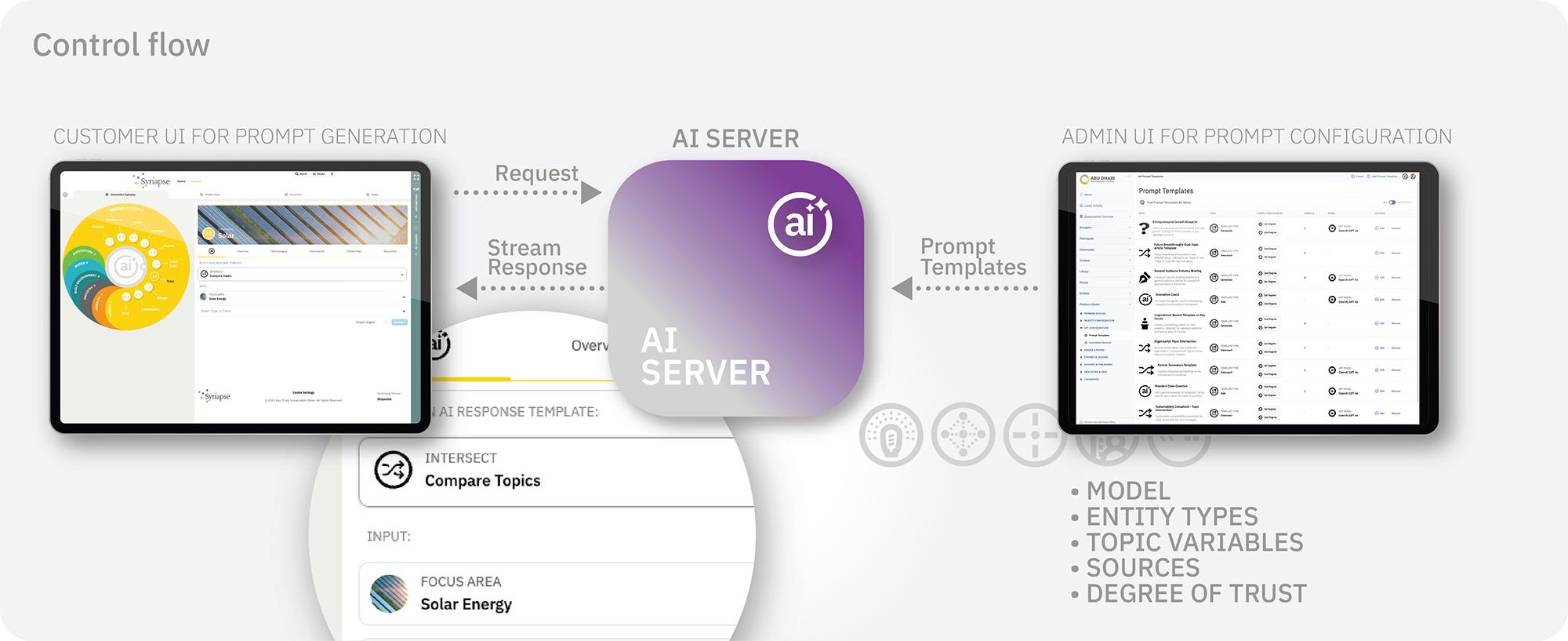
We specify each prompt template within a customer’s platform using variables that can be input via text or by drop-down selectors that show results from sets of taxonomies. The selections trigger queries to the vector-store to retrieve specific information, which then becomes the context for more informed AI responses. If a user is on a page that contains information related to a particular topic, the prompt template’s AI input variables will get auto-filled with that topic from the taxonomy in the frontend for the convenience of the user. Each prompt template also gets a set of system instructions that are set as rules for the AI to be aware of when generating a response.
The LLM provider and model can also be set per template. We’ve got to the point that as long as the provider’s API key has been set, we can instantiate any model in the backend. We have categorised foundation models from well-known providers in the backend so that if an API is down (you’d be surprised how often the OpenAI API goes down) a different provider with a similar model will respond to the user.

The architecture and implementation of our templating system has been well received by our customers and external stakeholders:
“I used the AI search across several topics and I found this brilliant. The synopsis provided, the topic summaries, potential partners and case studies were concise and an excellent read for all questions I asked.”
Knowledge Graph Entities and Vector Tagging
One of our key use cases is to identify organisations who are innovating on certain topics, to assist with partnership building. Another is to provide citations and links to sources across the platform, by topics and sub-topics, by country, and scientific papers. A drawback of a vector database is that it doesn’t recognise entities and relationships in the way knowledge graphs do. However, for any AI generated response we need to create a listing of entities it has referenced, by their type from the knowledge graph.
To achieve this we’ve introduced a knowledge graph tagging system during the ingestion of content and data. We've built the platform server on a knowledge graph. It tells the data ingestor which type of entities it is supplying, what connections they have to other entities, and other relational metadata which are then appended to the vectors via ingestion tagging. The AI Server is then able to deliver listings of knowledge graph entities to the front end interface, and link back to them on the platform.
This vector tagging methodology also lets us identify content ownership. We can ring-fence proprietary content, partner content, third party research and anything confidential. This enables us to connect content retrieval from the vector store with our permissions system. It means we can generate content within AI responses whilst citing ownership and IP attribution. We can also create ‘consulting namespaces’ for research-only purposes - or restrict the AI’s use of confidential material to those who have access rights. We call this our AI Degrees of Trust, and it’s also applied to the Prompt templates, per template.
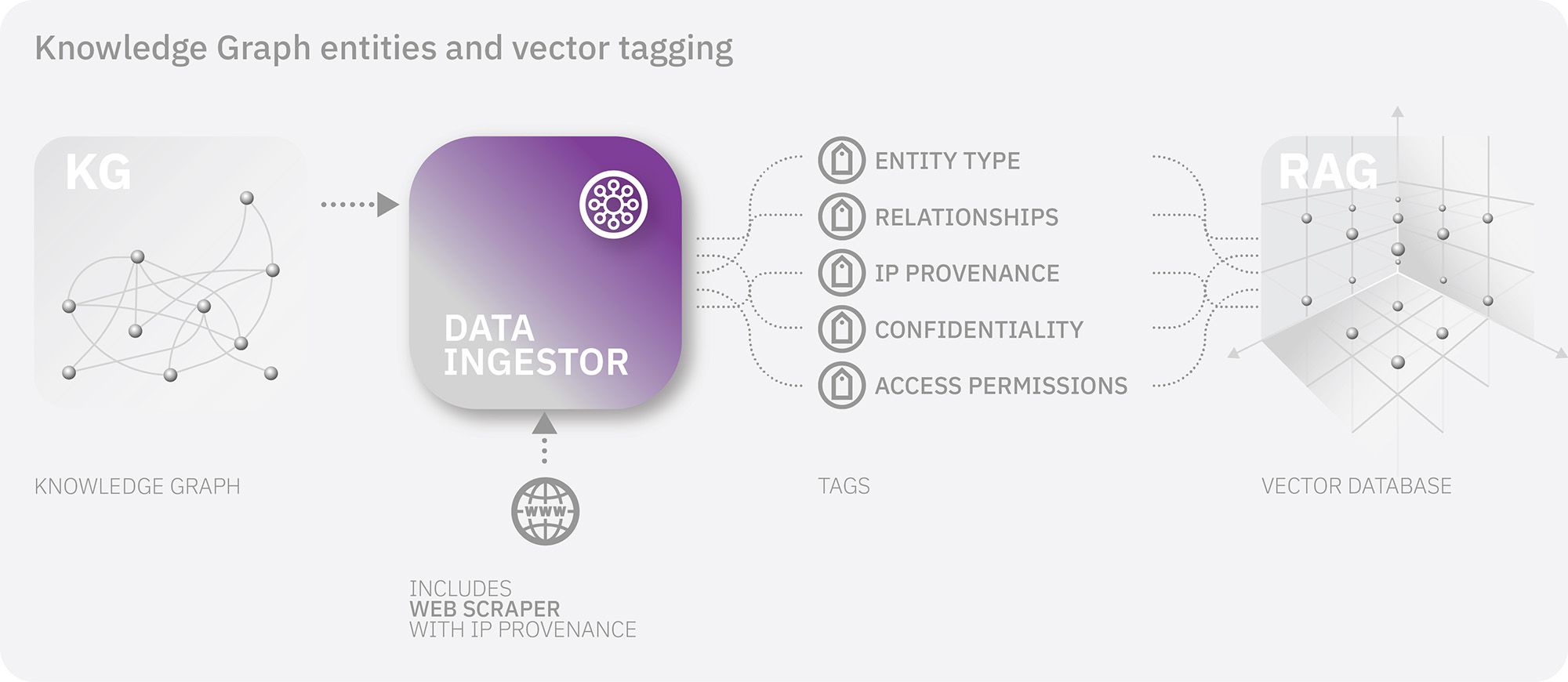
The vector document IDs maintain this entity-graph relationship. The relationship allows the data ingestor to make granular updates to the ingested knowledge-base in the vector store. This ensures that the data in the vector database remains consistent with platform data.
Towards an Agentic Future
The flexibility of this system of prompt templates, knowledge graph tagging, degrees of trust, permissions, variables, and control over the structure of the AI’s outputs sets us up for Agentic workflows.
Many of our Prompts will evolve into Agents. We have added an orchestration layer to our Prompt templates to enable on-demand tool-calling. So instead of creating Prompts that purely generate text outputs, the Prompts can instruct the model to invoke specific tools or functions that assist with reasoning, planning, delegating tasks and sharing information. These tools leverage the platform’s schema and taxonomy to enhance the quality of generated outputs. This will enable workflows that can handle complex tasks in real-world situations.
We have successfully tested this new Agentic AI approach to enhance the user experience and quality of generated outputs. With all the expertise and tools we’ve built along the way, we’re confident that it’ll become a valuable tool for planning and strategy development in the near future! Get in touch
Are you a business ecosystem with a unique and complex challenge? Do you need a digital platform to scale your knowledge, collaboration, and impact? We're ready to help.